
A Conversational AI Chatbot is Helping New Mothers Keep Healthy (#4)
Research in Translation

Introduction
Welcome back to ‘From the Computer to the Clinic’ - a newsletter about computational biology and its contributions to biomedical research.
In this newsletter, we explore how computational biology research can drive clinical progress. By sharing success stories in one disease area or domain of research, we aim to inspire the use of these successful approaches for other diseases and research areas also.
If you haven’t already, you can subscribe to this newsletter, or share it with friends and colleagues
Part IV
This is part IV of this series - if you missed parts I-III, you can find them on the home page of this newsletter.
In the 1980s, computer scientists developed a new kind of neural network architecture (a new way to arrange and link together the individual neurons in the network). It is called a recurrent neural network or RNN. Traditionally, artificial neural networks had been designed to take input data representing some individual or object and predict its identity or properties. For example, a neural network could be trained to take in a picture of an animal and predict that it is a dog or a cat. Or you could train a neural network to take a set of clinical variables (heart rate, blood pressure, body weight, levels of biological compounds in blood or tissue samples, etc.) and predict an individual’s risk for a certain disease.
These traditional networks work with singular inputs - snapshots in time. RNNs, in contrast, were designed to take in a series of data points collected over a period of time, using these past data points to predict the present or the future. The input data points fed into the RNN may be a set of past stock prices (to predict the current price), a string of daily temperatures (to predict the temperature of today), or a series of words in a sentence (to predict the next word).
This last application is exactly what the models that power AI chatbots are trying to do. They are trained so that you can ask them a question (or make a statement), and the AI chatbot predicts what word should come next, over and over again, until it has generated a response. If you provide enough data to these systems, they can accomplish this task extremely well (as the current iterations of chatbots like ChatGPT demonstrate).
Modern chatbots like ChatGPT and Penny the postpartum chatbot (see part I of this series) are not running on RNNs. Rather, they tend to use a newer architecture called the ‘transformer’. That said, the transformer was developed as an improvement on ‘long short-term memory’ (LSTM) networks, which are an evolved variant of the RNNs originally developed in the 80s. So taking a closer look at RNNs will provide strong intuition for how modern AI chatbots work. In fact, some of the early AI chatbots that generated a lot of excitement, as we will see later on in this series, did run on RNNs (we will focus on LSTM networks and transformers in future editions).
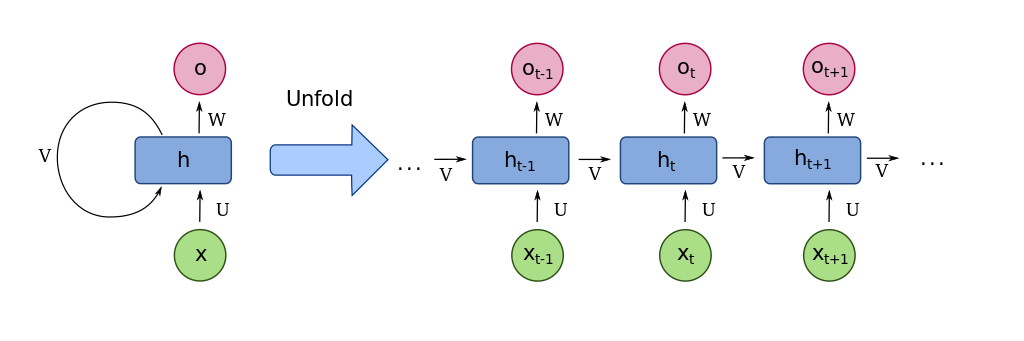
The architecture of an RNN is not much different from the traditional neural networks we covered in the previous part of this series. RNNs typically have an input layer, an output layer, and one or more hidden layers in between. The key innovation of the RNN is a feedback system that allows earlier data points in a series (earlier stock prices, temperatures, words) to influence later ones. This gives the RNN a capacity for memory, allowing it to mimic another central aspect of human cognition.
To get a feel for how data flows through the RNN, say that you have the daily temperature highs in New York City for the past week (77°F, 81°F, 79°F, etc.) and you want to predict today’s high temperature. You start with the first temperature in the series and feed it into the network. Similar to what we have seen before with traditional neural networks, this first temperature value will be transmitted from the input layer to the internal hidden layer, and modified along the way by weighting and an activation function. But then something new happens. Instead of this information (the resulting value from the activation function) traveling all the way through to the final output layer of the network, it will instead be stored in memory.
Next, the second temperature in the series flows through the network, and the stored information from the first temperature gets added to it. Then, the third temperature in the series is influenced by the combined information from the first and second, and so on, until the last temperature in the series goes through the network. The last temperature, influenced by all the temperatures before, will travel all the way through the network to the output layer, where the resulting value will indicate the model’s predicted temperature for today (for a more visual demonstration of how this works, check out this video)
{kind=link}
Now that we have the basic idea of how this process works for temperatures, we can think about how this would work for a series of words, like a question or message provided to a chatbot. But there is an additional challenge that we have to consider - figuring out how to present words to a neural network.
Neural networks work with numbers. Feeding stock prices or temperature values into a neural network is therefore relatively straightforward. Training neural networks to classify images is more complicated, but possible once you recognize that an image is just a grid of square pixels with different color values (to get a feel for this yourself, try downloading one of the images from this newsletter onto your computer, opening the file, and zooming in as far as possible - you will see that the image is really just a grid of different colored squares). The pixel values of an image, represented as numbers, can be fed into the model as an ordered list of numbers, starting with the first row of the grid, then the second, and so on.
In a similar way, each word in a sentence can be represented as a list of numbers (a ‘word vector’ or ‘word embedding’). You can think of this list of numbers as representing the properties of a word, just as the inputs to an image processing neural network represent the color of image pixels. For example, the first element in the list may indicate whether the word refers to an animate (e.g., a person) or inanimate object (e.g., a mountain), the second to the age of the object, the third to the grammatical use of the word, and so on. These word vectors can have thousands of elements each representing different properties, and words with similar meanings and/or grammatical uses will have similar lists of numbers. This idea that you can represent words as lists of numbers is a concept with its roots in the mid-20th century, but has become very popular in recent years with the rise of large language models like ChatGPT.
[I couldn’t find a good open source image related to word embeddings to include in the newsletter, but there is an excellent image at the start of this article that you should check out if you want a more visual understanding of the ideas in the last paragraph]
With these concepts covered, we now have the core ingredients necessary to build AI chatbots. There are, however, some key innovations from the past few decades that have made possible AI chatbots that sound human, are medically literate, and remember important details about its individual users. These we will cover in the next edition.
Stay tuned for part V…